





ML / AI Algorithm Development for Predictive Maintenance
How controlled machinery faults, synchronized vibration capture, and analyst-labelled features create useful training data for predictive-maintenance models.
The data problem behind predictive maintenance
Most predictive-maintenance algorithms fail quietly before the model is even trained. The issue is not usually architecture choice; it is the quality of the vibration data. Field faults are rare, operating conditions drift, labels are uncertain, and the same fault may appear different when speed, load, mounting, or sensor location changes.
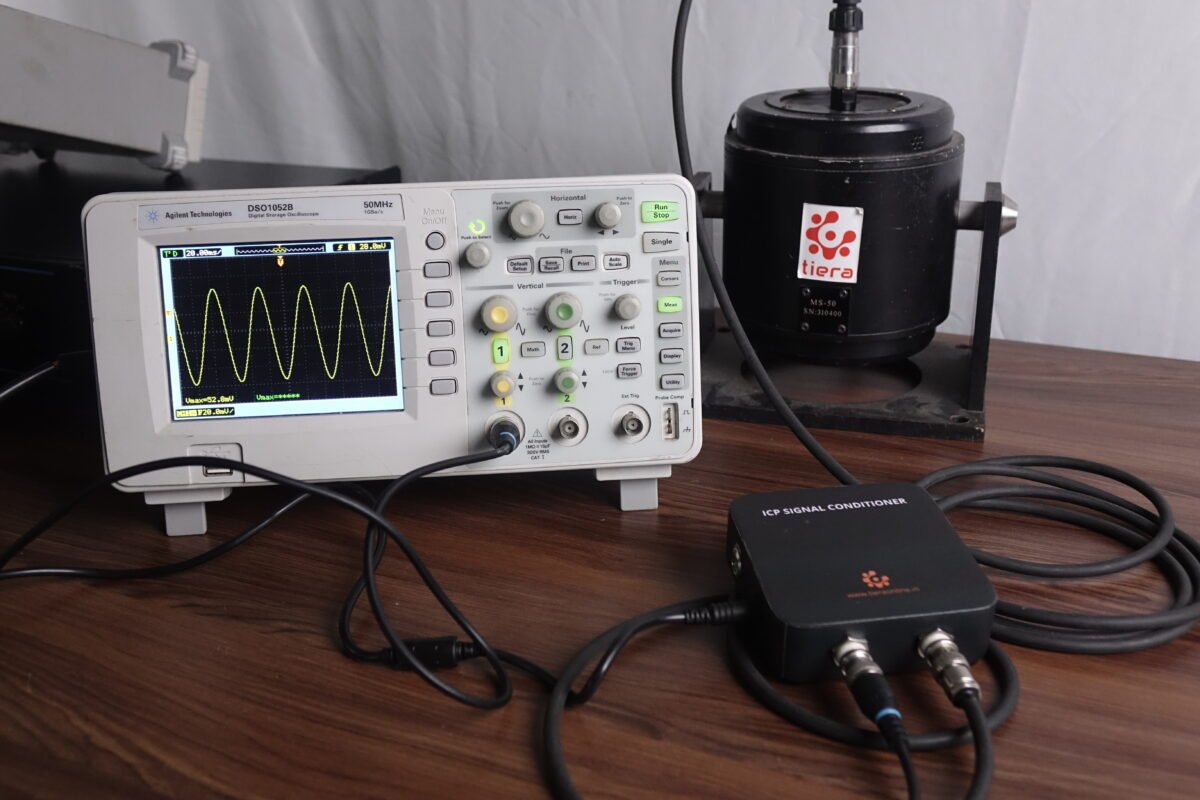
A research lab needs a repeatable way to generate known faults, capture them with a traceable reference chain, and keep the metadata clean enough for model training. That is where a controlled machinery fault simulator becomes more than a demonstration rig. It becomes a dataset engine.
A controlled fault simulator as a dataset engine
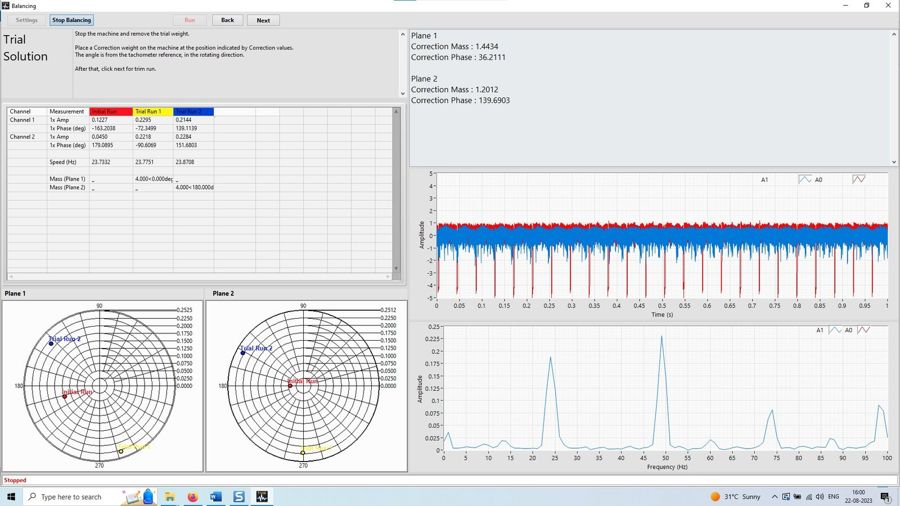
The TMFSS platform lets teams reproduce conditions such as unbalance, misalignment, looseness, bearing defects, gearbox faults, rub, and cavitation-like symptoms under controlled speed and load. Each run can be treated as a labelled experiment instead of a guessed field observation.
For ML teams, this matters because the label is known before the signal is captured. A bearing outer-race defect is not inferred later from a spectrum; it is deliberately installed, documented, and repeated across operating points.
What to capture for a useful model
A practical dataset should include raw time waveform, FFT spectrum, envelope spectrum where relevant, speed, load, sensor position, mounting method, acquisition settings, and the exact fault condition. The PhonoVibe DAQ and TVIB software chain can support this workflow by keeping the sensor-to-feature path consistent.
For neural networks, raw waveform windows are useful. For classical classifiers, engineered features such as band energy, crest factor, sideband ratios, RMS trend, and bearing-frequency markers can be exported and audited. The strongest workflow usually keeps both.
A lab workflow universities can publish
Start with baseline healthy runs at multiple speeds. Add one controlled fault at a time. Repeat each condition across several runs, then reserve some speeds and severity levels as hold-out validation data. This gives students and researchers a dataset that can support papers, demos, and algorithm benchmarking.
The goal is not to make the lab look like every plant in the world. The goal is to build a known, repeatable, instrumented environment where the algorithm's behavior can be understood before it is trusted in the field.